Week Learning Objectives
By the end of this module, you will be able to
- Explain the components of a random intercept model
- Interpret intraclass correlations
- Use the design effect to decide whether MLM is needed
- Explain why ignoring clustering (e.g., regression) leads to inflated chances of Type I errors
- Describe how MLM pools information to obtain more stable inferences of groups
Task Lists
- Review the resources (lecture videos and slides)
- Complete the assigned readings
- Snijders & Bosker ch 3.1–3.4, 4.1–4.5, 4.8
- Attend the Thursday session and participate in the class exercise
- Complete Homework 3
Lecture
Slides
You can view and download the slides here: PDF
Overview
Check your learning: Here’s a snapshot of the sleepstudy
data:
Reaction Days Subject
1 249.6 0 308
2 258.7 1 308
3 250.8 2 308
11 222.7 0 309
12 205.3 1 309
13 203.0 2 309
21 199.1 0 310
22 194.3 1 310
23 234.3 2 310where Subject is the cluster ID. Is Days a
level-1 or a level-2 variable?
Unconditional Random Intercept Model
Equations
Check your learning: \(u_{0j}\) is the new term in a multilevel model (compared to regression). Is it a level-1 or a level-2 deviation variable?
Path diagram
Check your learning: For the diagram in the video, which one is an actual variable in the data?
Fixed and Random Effects
Check your learning: For the unconditional model, which of the following is a fixed effect?
The Intraclass Correlation
Note: On the slide around the 9 minute mark, the numbers labeled the “Std.Dev.” is just the square root of the variance components. That is, the standard deviation of the school means and the within-school standard deviation.
Check your learning: For a study, if \(\tau^2_0 = 5\), \(\sigma^2 = 10\), what is the ICC?
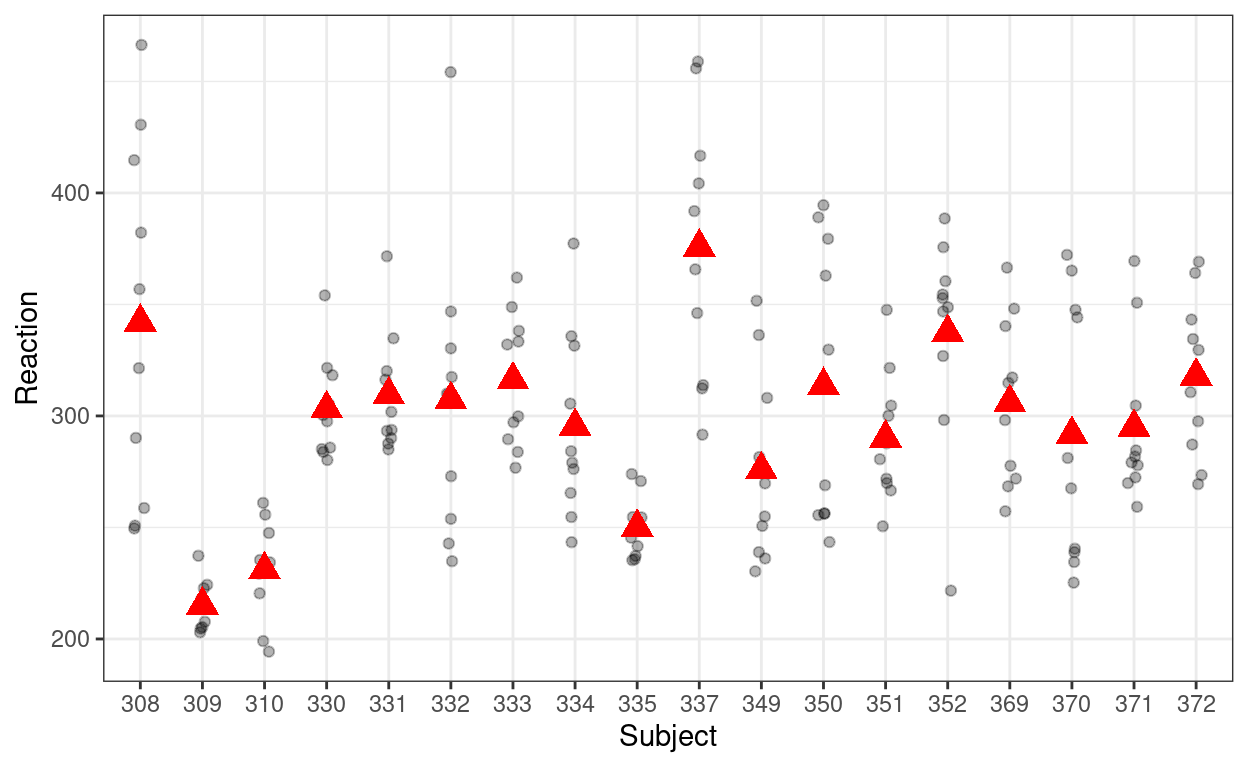
Check your learning: The graph below shows the distribution of the
Reaction variable in the sleepstudy data. What
do you think is a good guess for the its ICC?
Empirical Bayes Estimates
Note: OLS = ordinary least squares, the estimation method commonly used in regular regression.
Thinking exercise: When \(\sigma^2 / n_j = 0\), \(\lambda_j = 1\), and the empirical Bayes estimate will be the same as the sample school mean, meaning that there is no borrowing of information. Why is there no need to borrow information in this situation?
Adding a Level-2 Predictor
Note that the ses was standardized in the data set,
meaning that ses = 0 is at the sample mean, and
ses = 1 means one standard deviation above the mean.
Check your learning: In regression, the independent observation assumption means that
The design effect
Practice yourself: Compute the design effect for mathach
for the HSB data. Which of the following is the closest to your
computation?
Bonus Challenge: What is the design effect for a longitudinal study of 5 waves with 30 individuals, and with an ICC for the outcome of 0.5?
Aggregation
While disaggregation yields results with standard errors being too small, aggregation generally results in standard errors that are slightly larger. The main problem of aggregation, however, is that it removes all the information in the lower level, so level-1 predictors cannot be studied. MLM avoids problems of both disaggregation and aggregation.
Standard error estimates under OLS and MLM
This part is optional but gives a mathematical explanation of why OLS underestimates the standard error
Model equations
Check your learning: In the level-2 equation with
meanses as the predictor, what is the outcome variable?
MLM with a level-2 predictor in R
Check your learning: How do you interpret the coefficient for
meanses?
Statistical inference
Note: If the 95% CI exlcudes zero, there is evidence that the predictor has a nonzero relation with the outcome.
Check your learning: By default, what type of confidence interval is
computed by the lme4 package?