\[ \newcommand{\bv}[1]{\boldsymbol{\mathbf{#1}}} \]
Click here to download the Rmd file: week2-review-multiple-regression.Rmd
Simulation
Practice yourself: From the simulation code provided, try to increase the sample size from 62 to something larger, like 200. How does this affect the uncertainty in the sample slopes?
Load Packages and Import Data
You can use add the message=FALSE option to suppress the
package loading messages
# To install a package, run the following ONCE (and only once on your computer)
# install.packages("psych")
library(psych, include.only = "pairs.panels") # for scatterplot matrix
library(here) # makes reading data more consistent
library(tidyverse) # for data manipulation and plotting
library(car) # some useful functions for regression
library(modelsummary) # for making tables
library(sjPlot) # for plotting slopes
library(interactions) # for plotting interactions
theme_set(theme_bw()) # Theme; just my personal preference
Import Data
First, download the data file salary.txt from https://raw.githubusercontent.com/marklhc/marklai-pages/master/data_files/salary.txt,
and import the data. A robust way to do so is to download the data to a
folder called data_files under the project directory, and
then use the here package. This avoids a lot of data import
issues that I’ve seen.
# The `here()` function forces the use of the project directory
here("data_files", "salary.txt")
# Read in the data
salary_dat <- read.table(here("data_files", "salary.txt"), header = TRUE)
Alternatively, from the menu, click File →
Import Dataset → From Text (base)..., and
select the file.
# Show the data
salary_dat
># id time pub sex citation salary
># 1 1 3 18 1 50 51876
># 2 2 6 3 1 26 54511
># 3 3 3 2 1 50 53425
># 4 4 8 17 0 34 61863
># 5 5 9 11 1 41 52926
># 6 6 6 6 0 37 47034
># 7 7 16 38 0 48 66432
># 8 8 10 48 0 56 61100
># 9 9 2 9 0 19 41934
># 10 10 5 22 0 29 47454
># 11 11 5 30 1 28 49832
># 12 12 6 21 0 31 47047
># 13 13 7 10 1 25 39115
># 14 14 11 27 0 40 59677
># 15 15 18 37 0 61 61458
># 16 16 6 8 0 32 54528
># 17 17 9 13 1 36 60327
># 18 18 7 6 0 69 56600
># 19 19 7 12 1 47 52542
># 20 20 3 29 1 29 50455
># 21 21 7 29 1 35 51647
># 22 22 5 7 0 35 62895
># 23 23 7 6 0 18 53740
># 24 24 13 69 0 90 75822
># 25 25 5 11 0 60 56596
># 26 26 8 9 1 30 55682
># 27 27 8 20 1 27 62091
># 28 28 7 41 1 35 42162
># 29 29 2 3 1 14 52646
># 30 30 13 27 0 56 74199
># 31 31 5 14 0 50 50729
># 32 32 3 23 0 25 70011
># 33 33 1 1 0 35 37939
># 34 34 3 7 0 1 39652
># 35 35 9 19 0 69 68987
># 36 36 3 11 0 69 55579
># 37 37 9 31 0 27 54671
># 38 38 3 9 0 50 57704
># 39 39 4 12 1 32 44045
># 40 40 10 32 0 33 51122
># 41 41 1 26 0 45 47082
># 42 42 11 12 0 54 60009
># 43 43 5 9 0 47 58632
># 44 44 1 6 0 29 38340
># 45 45 21 39 0 69 71219
># 46 46 7 16 1 47 53712
># 47 47 5 12 1 43 54782
># 48 48 16 50 0 55 83503
># 49 49 5 18 0 33 47212
># 50 50 4 16 1 28 52840
># 51 51 5 5 0 42 53650
># 52 52 11 20 0 24 50931
># 53 53 16 50 1 31 66784
># 54 54 3 6 1 27 49751
># 55 55 4 19 1 83 74343
># 56 56 4 11 1 49 57710
># 57 57 5 13 0 14 52676
># 58 58 6 3 1 36 41195
># 59 59 4 8 1 34 45662
># 60 60 8 11 1 70 47606
># 61 61 3 25 1 27 44301
># 62 62 4 4 1 28 58582You can see the description of the variables here: https://rdrr.io/cran/MBESS/man/prof.salary.html
Quick Scatterplot Matrix
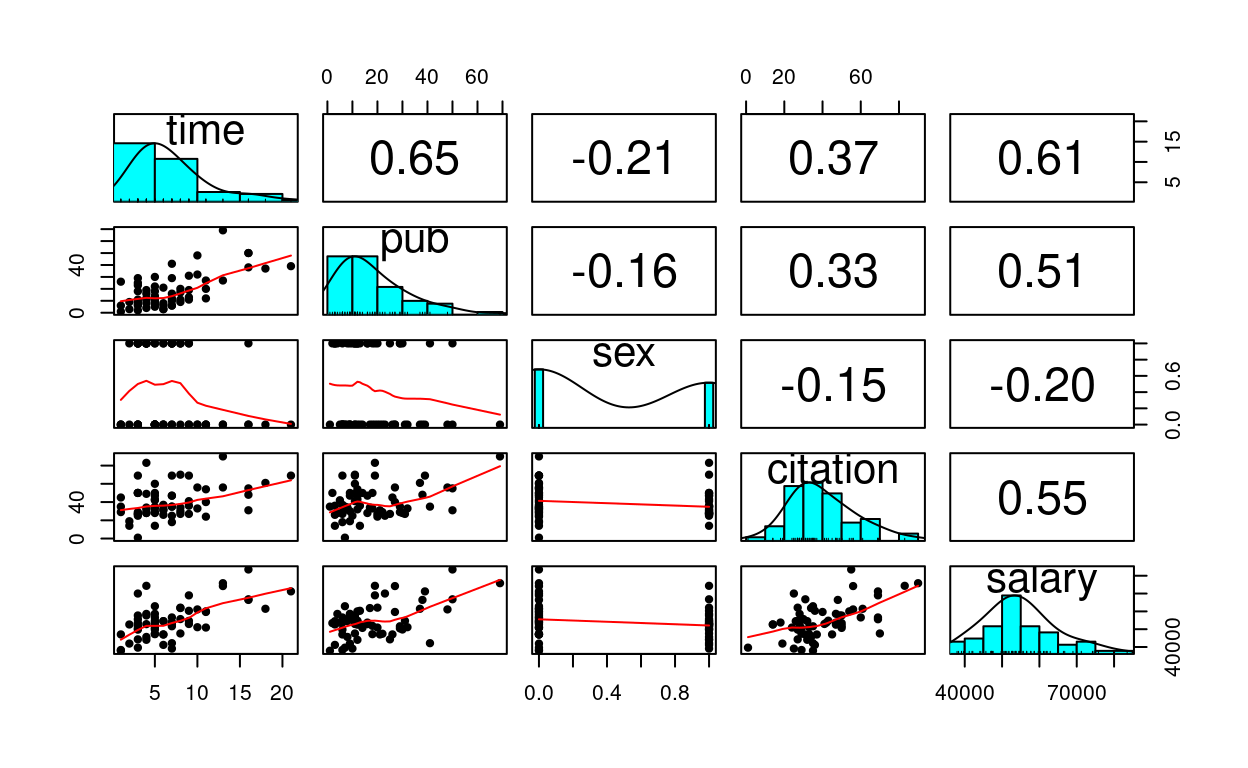
Import to screen your data before any statistical modeling
pairs.panels(salary_dat[ , -1], # not plotting the first column
ellipses = FALSE)
1. Linear Regression of
salary on pub
Visualize the data
# Visualize the data ("gg" stands for grammar of graphics)
p1 <- ggplot(salary_dat, # specify data
# aesthetics: mapping variable to axes)
aes(x = pub, y = salary)) +
# geom: geometric objects, such as points, lines, shapes, etc
geom_point()
# Add a smoother geom to visualize mean salary as a function of pub
p1 + geom_smooth()
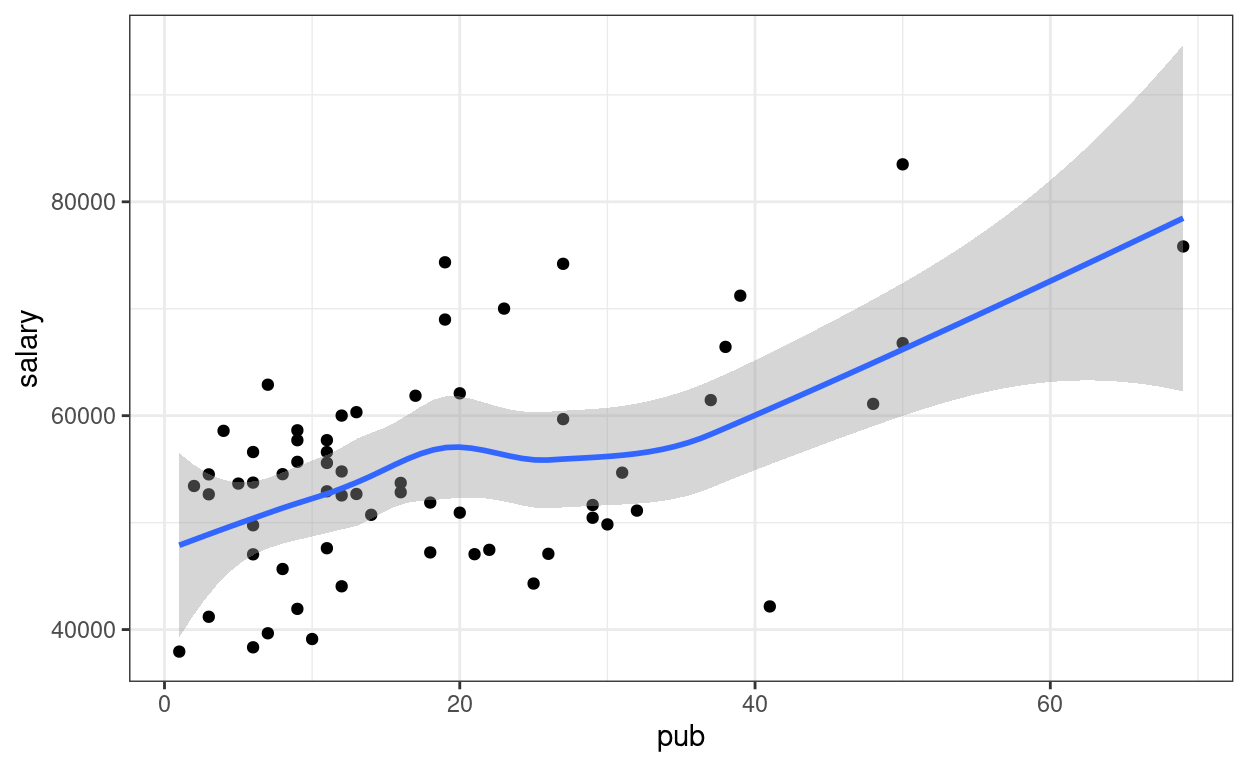
A little bit of non-linearity on the plot. Now fit the regression model
Linear regression
You can type equations (with LaTeX; see a quick reference).
P.S. Use \text{} to specify variable names
P.S. Pay attention to the subscripts
\[\text{salary}_i = \beta_0 + \beta_1 \text{pub}_i + e_i\]
- Outcome:
salary - Predictor:
pub - \(\beta_0\): regression intercept
- \(\beta_1\): regression slope
- \(e\): error
# left hand side of ~ is outcome; right hand side contains predictors
# salary ~ (beta_0) * 1 + (beta_1) * pub
# remove beta_0 and beta_1 to get the formula
m1 <- lm(salary ~ 1 + pub, data = salary_dat)
# In R, the output is not printed out if it is saved to an object (e.g., m1).
# Summary:
summary(m1)
>#
># Call:
># lm(formula = salary ~ 1 + pub, data = salary_dat)
>#
># Residuals:
># Min 1Q Median 3Q Max
># -20660 -7397 334 5314 19239
>#
># Coefficients:
># Estimate Std. Error t value Pr(>|t|)
># (Intercept) 48439.1 1765.4 27.44 < 2e-16 ***
># pub 350.8 77.2 4.55 2.7e-05 ***
># ---
># Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
>#
># Residual standard error: 8440 on 60 degrees of freedom
># Multiple R-squared: 0.256, Adjusted R-squared: 0.244
># F-statistic: 20.7 on 1 and 60 DF, p-value: 2.71e-05Visualize fitted regression line:
p1 +
# Non-parametric fit
geom_smooth(se = FALSE) +
# Linear regression line (in red)
geom_smooth(method = "lm", col = "red")
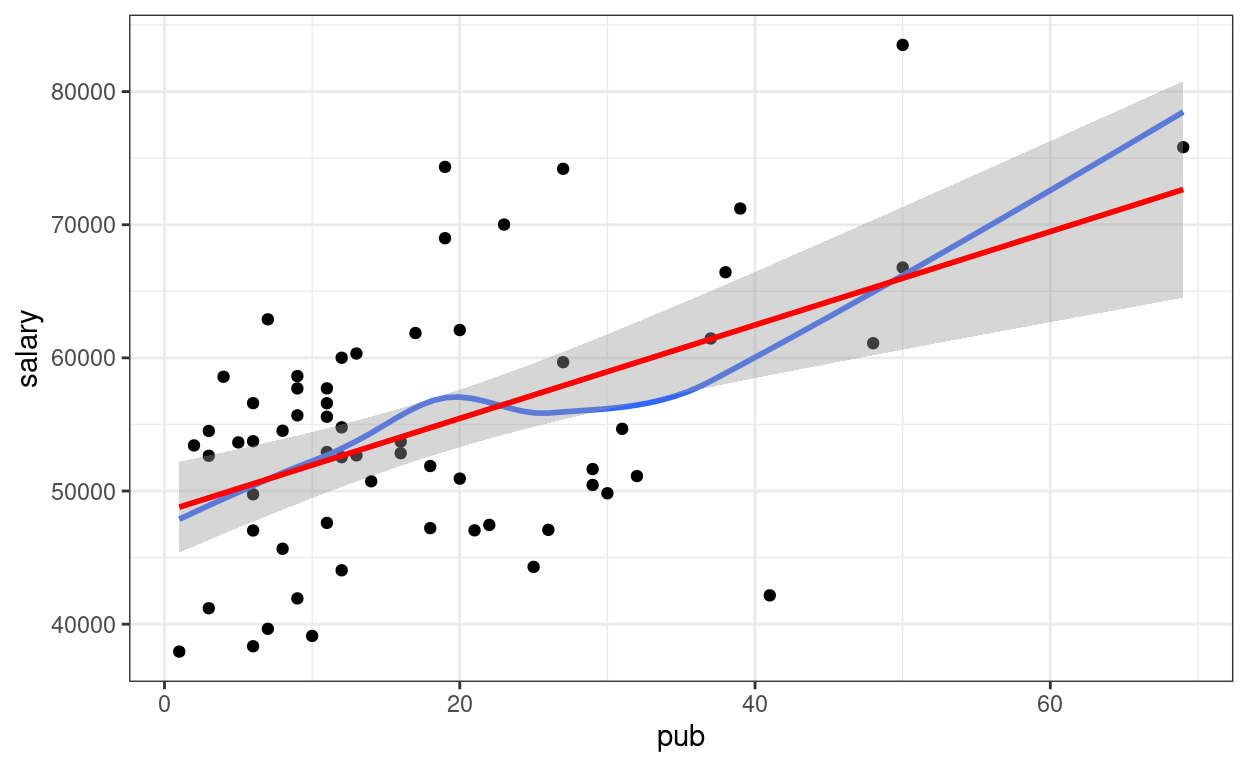
Confidence intervals
# Confidence intervals
confint(m1)
># 2.5 % 97.5 %
># (Intercept) 44907.7 51970.4
># pub 196.4 505.2Interpretations
Based on our model, faculty with one more publication have predicted salary of $350.8, 95% CI [$196.4, $505.2], higher than those with one less publication.
But what do the confidence intervals and the standard errors mean? To understanding what exactly a regression model is, let’s run some simulations.
Simulations
Before you go on, take a look on a brief introductory video by Clark Caylord on Youtube on simulating data based on a simple linear regression model.
To my delight, I also found out a gentle introduction of simulation method by one of our clinical science students at USC (Thanks Kayla!). You can access it through the USC library here (Sign-on required). Here’s the citation:
Tureson, K. & Odland, A. (2018). Monte Carlo simulation studies. In B. Frey (Ed.),The SAGE Encyclopedia of Educational Research, Measurement, and Evaluation. Thousand Oaks, CA: SAGE Publications.
Based on the analyses, the sample regression line is \[\widehat{\text{salary}} = 48439.09 + 350.80
\text{pub}.\] The numbers are only sample estimates as there are
sampling errors. However, if we assume that this line truly describe the
relation between salary and pub, then we can
simulate some fake data, which represents what we could have obtained in
a different sample.
Going back to the equation \[\text{salary}_i = \beta_0 + \beta_1 \text{pub}_i
+ e_i,\] the only thing that changes across different samples,
based on the statistical model, is \(e_i\). Conceptually, you can think of the
error term \(e_i\) as the
deviation of person \(i\)’s salary from
the mean salary of everyone in the population who has the same number of
publications as person \(i\).
Here we assume that \(e_i\) is normally
distributed, written as \(e_i \sim N(0,
\sigma)\), where \(\sigma\)
describes the conditional standard deviation (i.e., the standard
deviation across individuals who have the same number of publications).
From the regression results, \(\sigma\)
is estimated as the Residual standard error = 8,440.
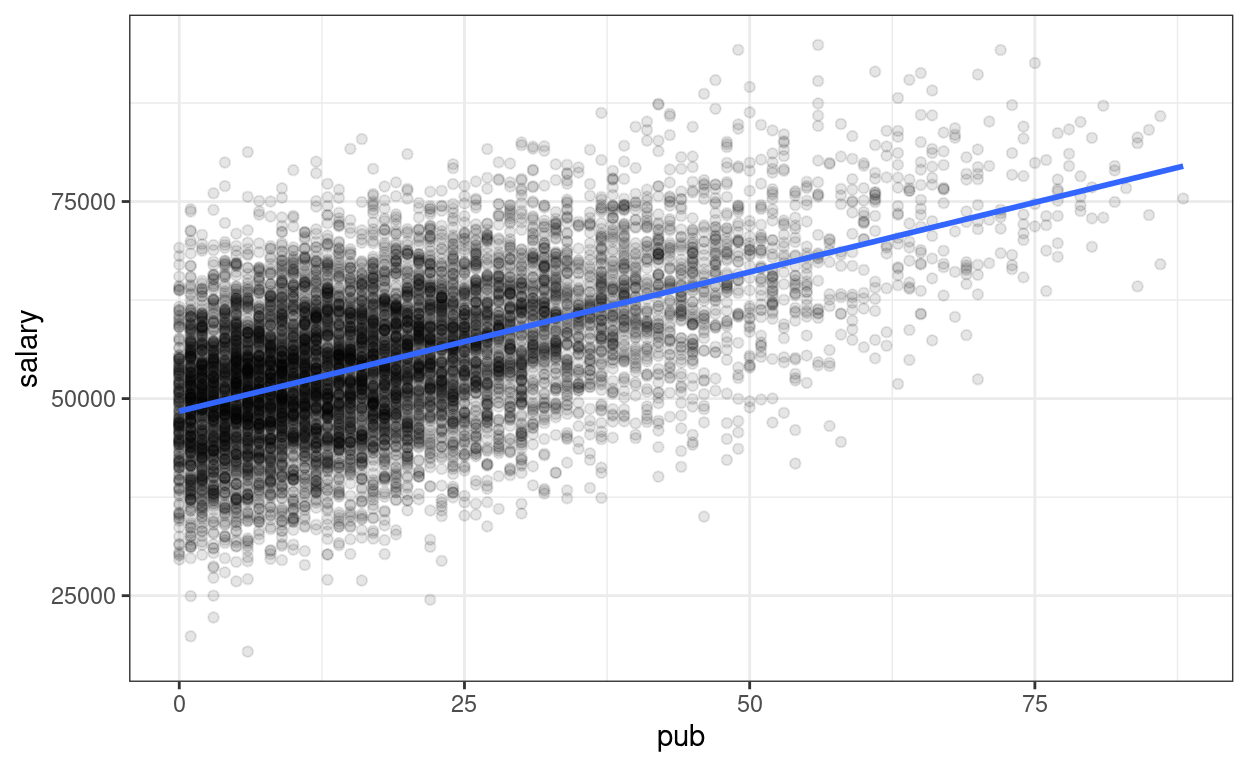
Based on these model assumptions, we can imagine a large population, say with 10,000 people
# Simulating a large population. The code in this chunk
# is not essential for conceptual understanding
Npop <- 10000
beta0 <- 48439.09
beta1 <- 350.80
sigma <- 8440
# Simulate population data
simulated_population <- tibble(
# Simulate population pub
pub = local({
dens <- density(c(-salary_dat$pub, salary_dat$pub),
bw = "SJ",
n = 1024
)
dens_x <- c(0, dens$x[dens$x > 0])
dens_y <- c(0, dens$y[dens$x > 0])
round(
approx(
cumsum(dens_y) / sum(dens_y),
dens_x,
runif(Npop)
)$y
)
}),
# Simulate error
e = rnorm(Npop, mean = 0, sd = sigma)
)
# Compute salary variable
simulated_population$salary <-
beta0 + beta1 * simulated_population$pub + simulated_population$e
# Plot
p_pop <- ggplot(
data = simulated_population,
aes(x = pub, y = salary)
) +
geom_point(alpha = 0.1) +
# Add population regression line in blue
geom_smooth(se = FALSE, method = "lm")
p_pop
Now, we can simulate some fake (but plausible) samples. An important
thing to remember is we want to simulate data that have the same
size as the original sample, because we’re comparing to other
plausible samples with equal size. In R there is a handy
simulate() function to do that.
simulated_salary <- simulate(m1)
# Add simulated salary to the original data
# Note: the simulated variable is called `sim_1`
sim_data1 <- bind_cols(salary_dat, simulated_salary)
# Show the first six rows
head(sim_data1)
># id time pub sex citation salary sim_1
># 1 1 3 18 1 50 51876 62700
># 2 2 6 3 1 26 54511 63635
># 3 3 3 2 1 50 53425 38307
># 4 4 8 17 0 34 61863 62060
># 5 5 9 11 1 41 52926 48844
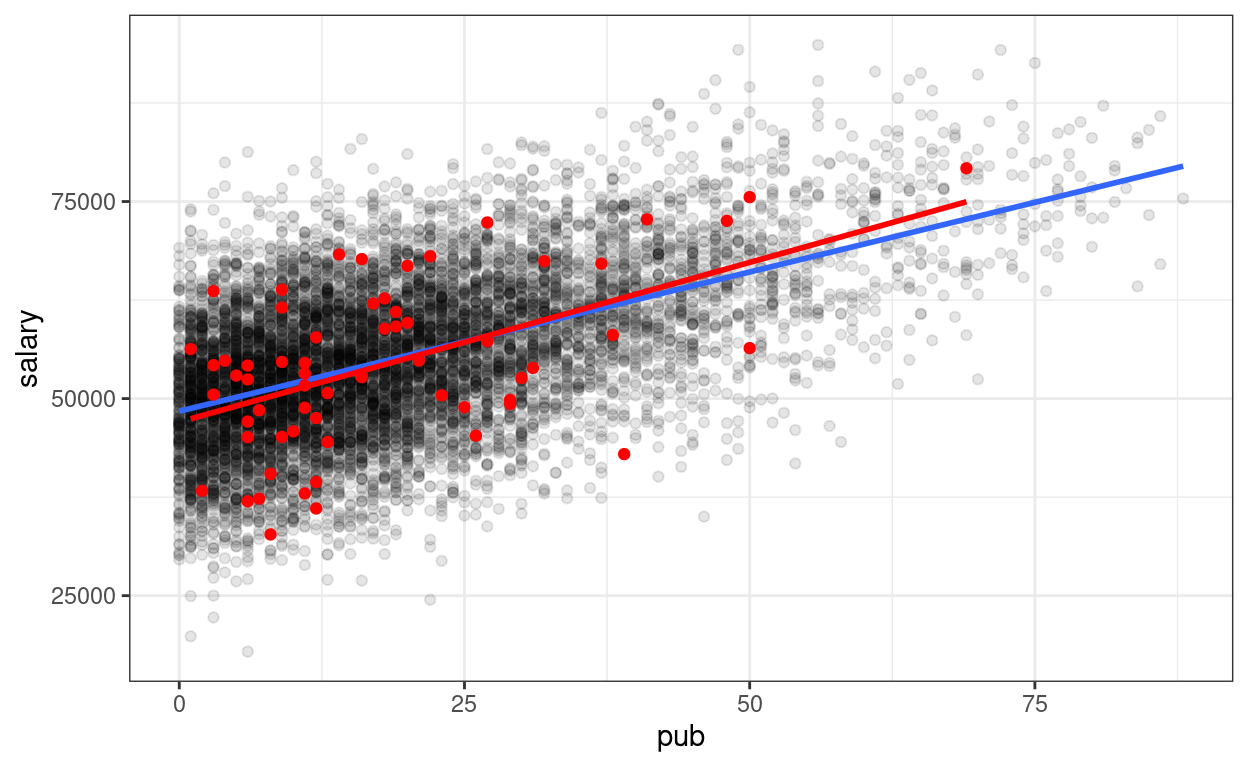
># 6 6 6 6 0 37 47034 45108# Plot the data (add on to the population)
p_pop +
geom_point(data = sim_data1,
aes(x = pub, y = sim_1),
col = "red") +
# Add sample regression line
geom_smooth(data = sim_data1,
aes(x = pub, y = sim_1),
method = "lm", se = FALSE, col = "red")
# To be more transparent, here's what the simulate() function essentially is
# doing
sample_size <- nrow(salary_dat)
sim_data1 <- tibble(
pub = salary_dat$pub,
# simulate error
e = rnorm(sample_size, mean = 0, sd = sigma)
)
# Compute new salary data
sim_data1$sim_1 <- beta0 + beta1 * sim_data1$pub + sim_data1$e
As you can see, the sample regression line in red is different from the blue line.
Drawing 100 samples
Let’s draw more samples
num_samples <- 100
simulated_salary100 <- simulate(m1, nsim = num_samples)
# Form a giant data set with 100 samples
sim_data100 <- bind_cols(salary_dat, simulated_salary100) %>%
pivot_longer(sim_1:sim_100,
names_prefix = "sim_",
names_to = "sim",
values_to = "simulated_salary"
)
# Plot by samples
p_sim100 <- ggplot(
sim_data100,
aes(x = pub, y = simulated_salary, group = sim)
) +
geom_point(col = "red", alpha = 0.1) +
geom_smooth(col = "red", se = FALSE, method = "lm")
# Use gganimate (this takes some time to render)
library(gganimate)
p_sim100 + transition_states(sim) +
ggtitle("Simulation {frame} of {nframes}")
anim_save(here::here("sim-100-samples.gif"))
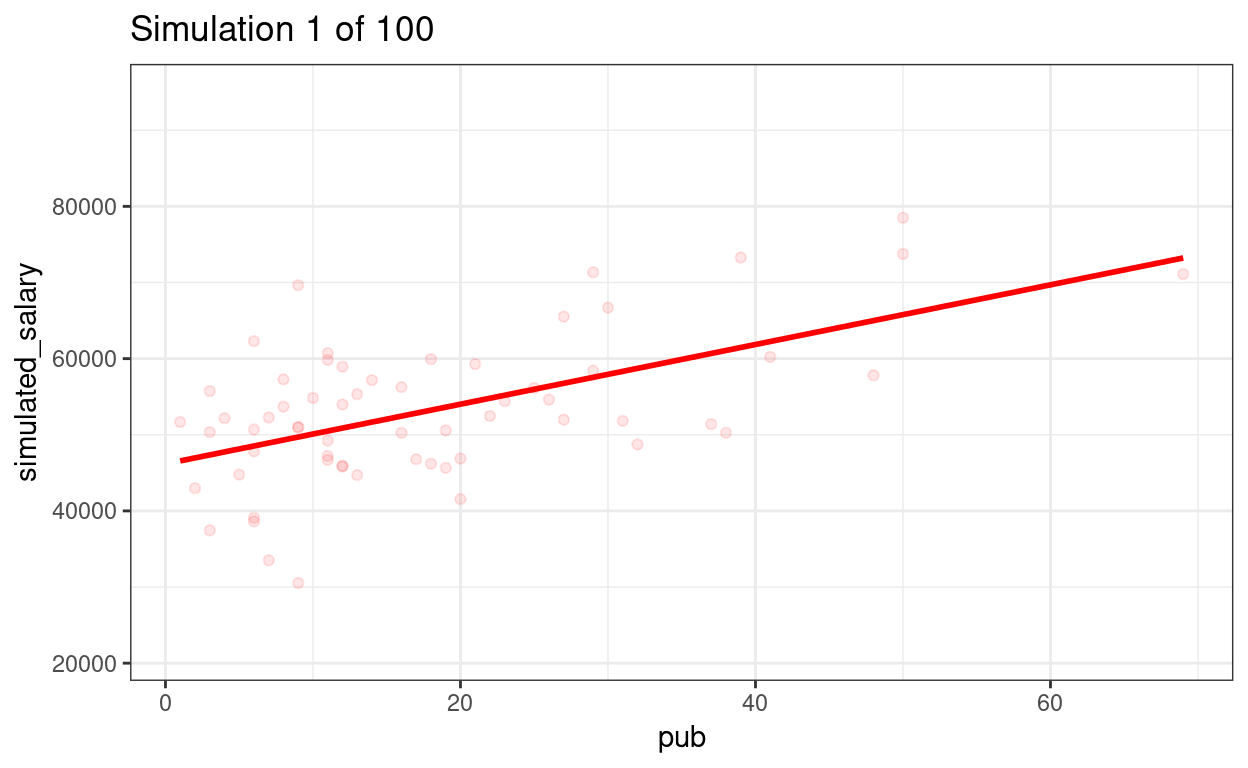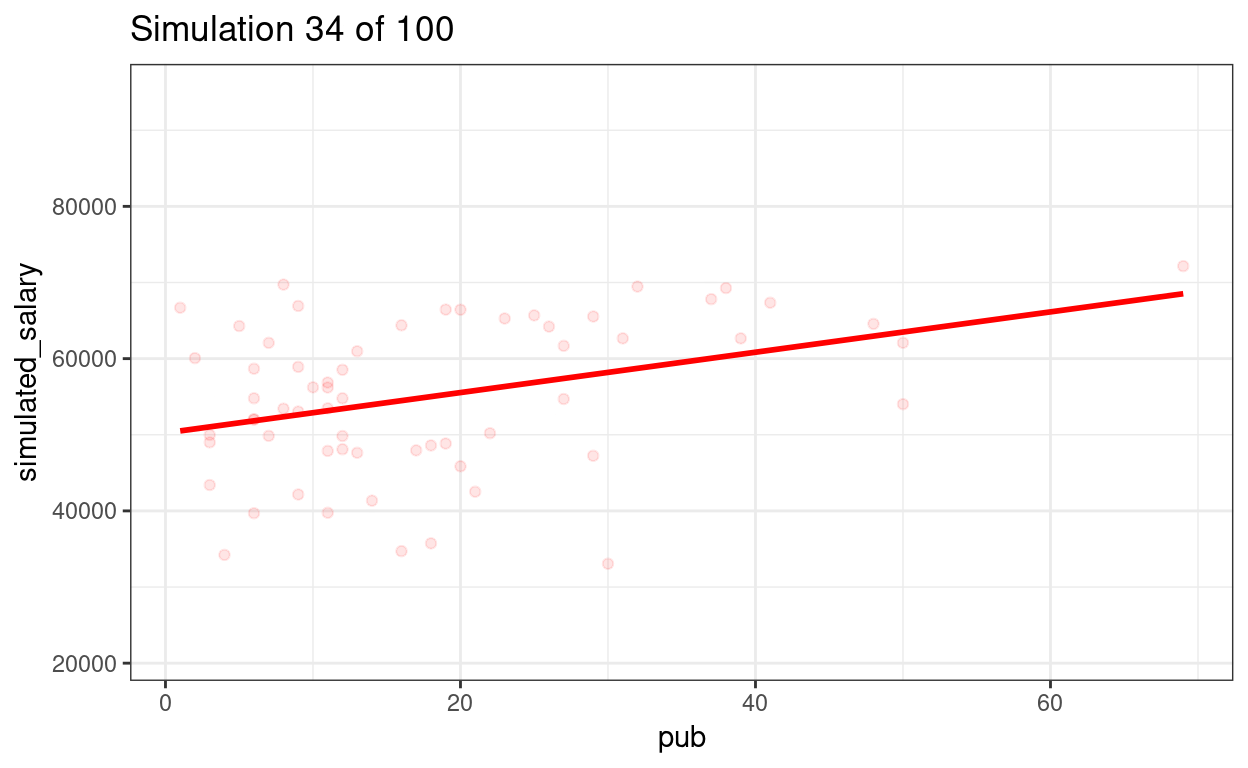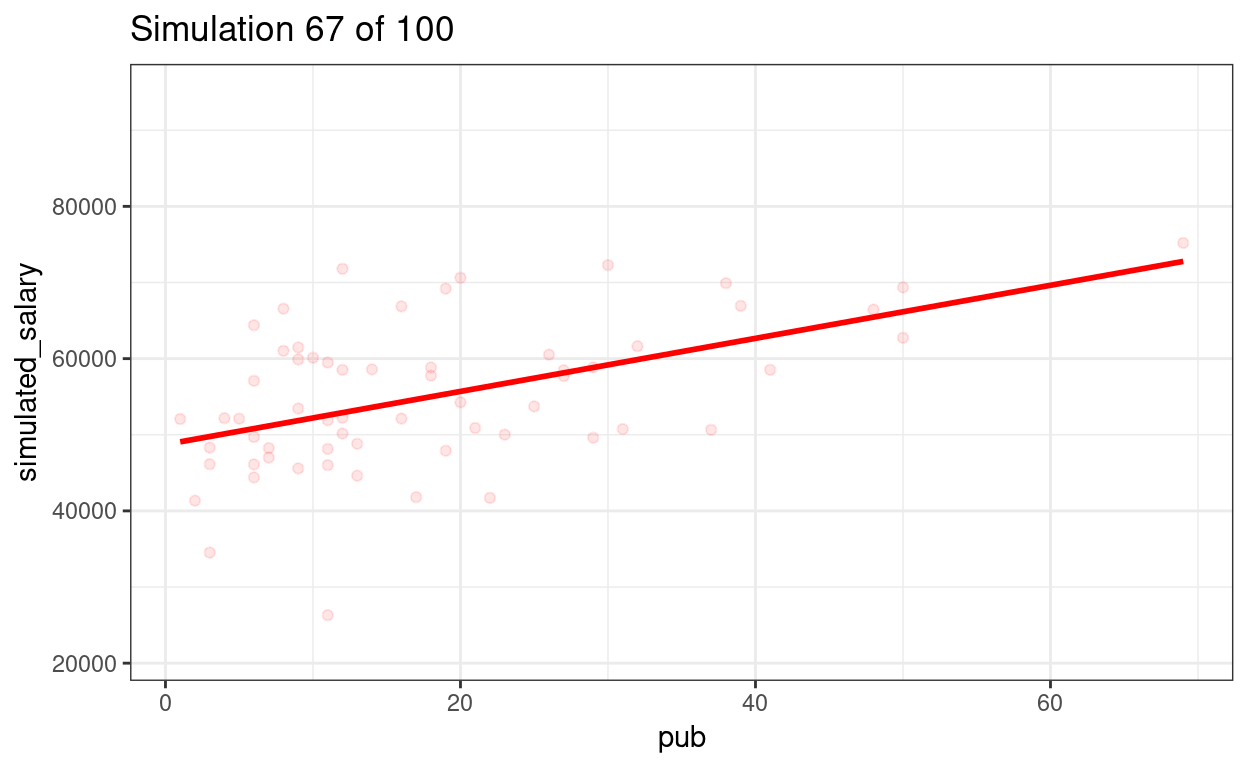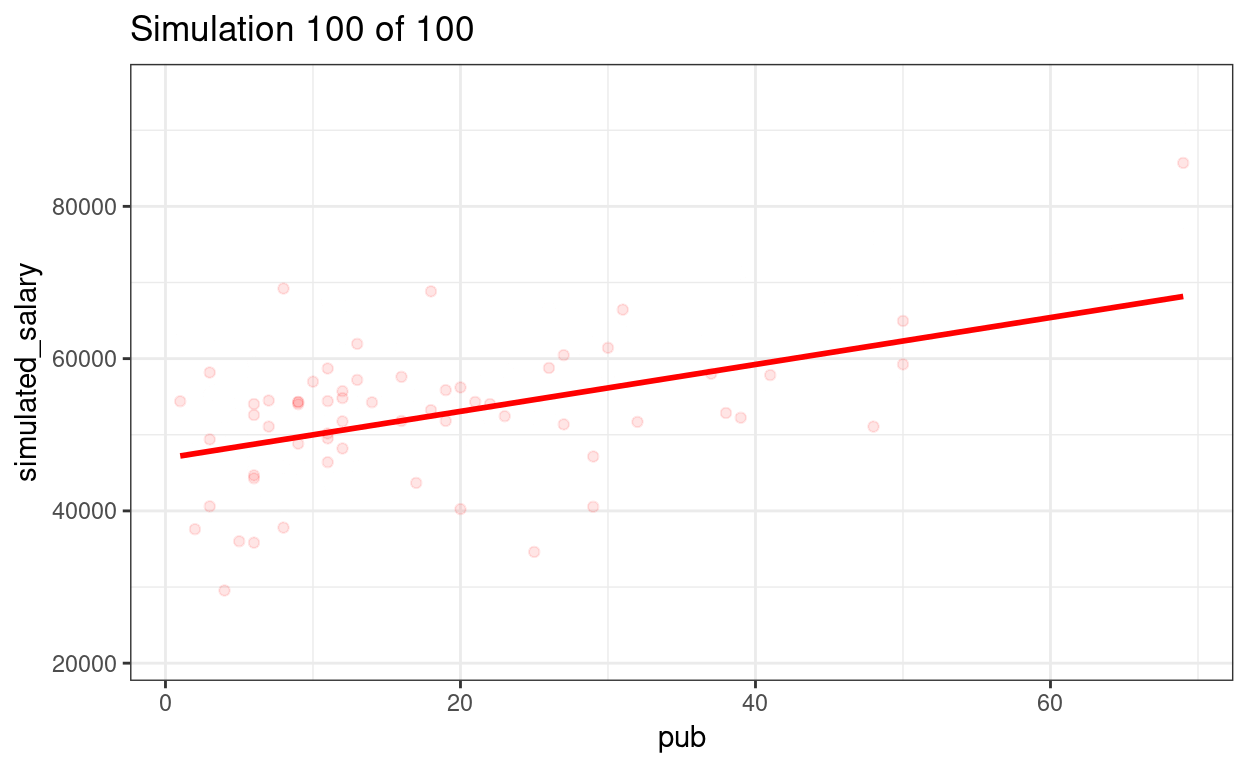
We can show the regression lines for all 100 samples
ggplot(sim_data100,
aes(x = pub, y = simulated_salary, group = sim)) +
stat_smooth(
geom = "line",
col = "red",
se = FALSE,
method = "lm",
alpha = 0.4
)
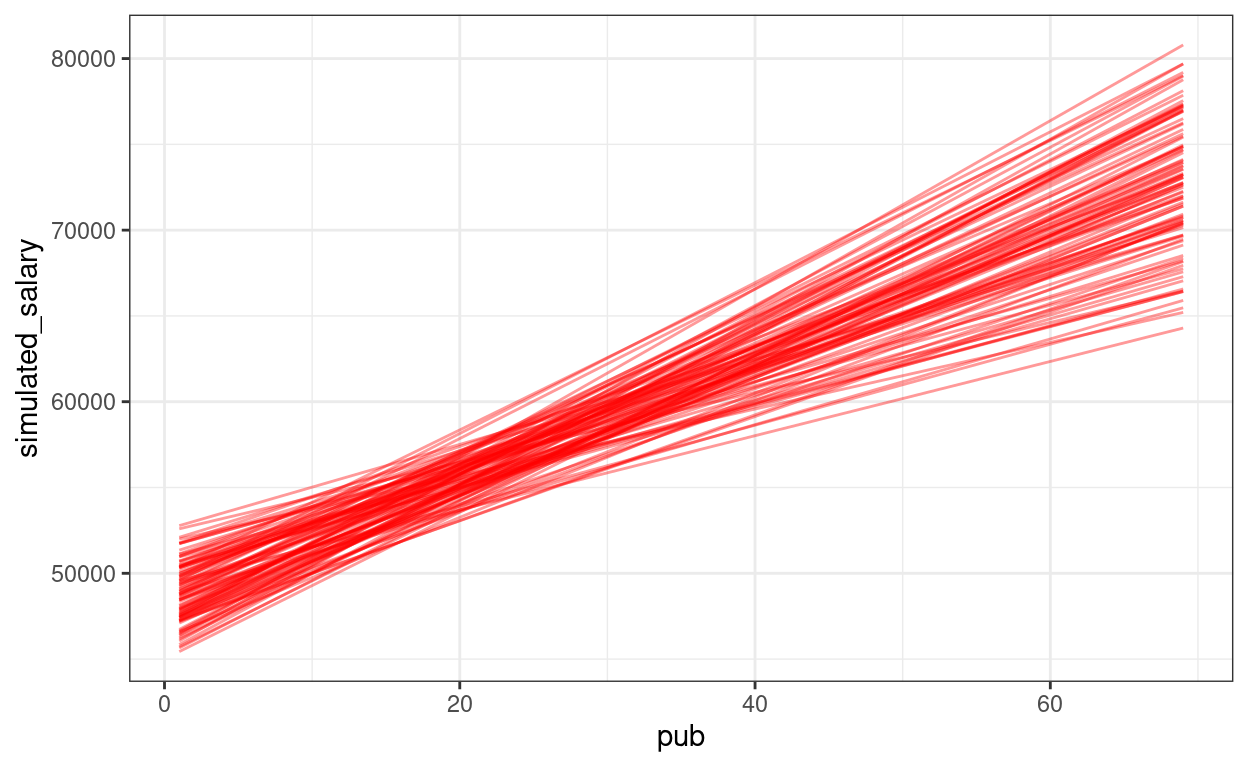
The confidence intervals of the intercept and the slope how much uncertainty there is.
\(p\) values
Now, we can also understand the \(p\) value for the regression slope of
pub is. Remember that the \(p\) value is the probability that, if the
regression slope of pub is zero (i.e., no association), how
likely/unlikely would we get the sample slope (i.e., 350.80) in our
data. So now we’ll repeat the simulation, but without pub
as a predictor (i.e., assuming \(\beta_1 =
0\)).
num_samples <- 100
m0 <- lm(salary ~ 1, data = salary_dat) # null model
simulated_salary100_null <- simulate(m0, nsim = num_samples)
# Form a giant data set with 100 samples
sim_null100 <- bind_cols(salary_dat, simulated_salary100_null) %>%
pivot_longer(sim_1:sim_100,
names_prefix = "sim_",
names_to = "sim",
values_to = "simulated_salary")
# Show the null slopes
ggplot(data = salary_dat,
aes(x = pub, y = salary)) +
stat_smooth(
data = sim_null100,
aes(x = pub, y = simulated_salary, group = sim),
geom = "line",
col = "darkgrey",
se = FALSE,
method = "lm"
) +
geom_smooth(method = "lm", col = "red", se = FALSE) +
geom_point()
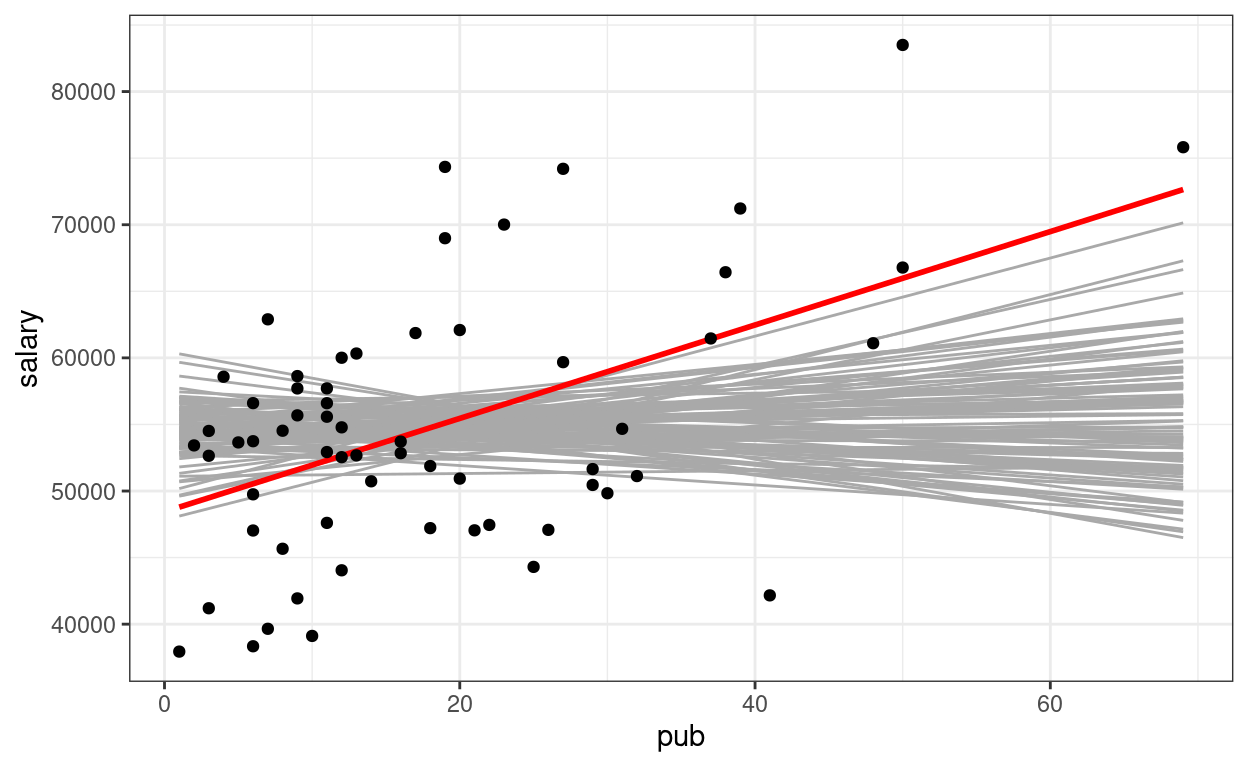
So you can see the sample slope is larger than what you would expect to see if the true slope is zero. So the \(p\) value is very small, and the result is statistically significant (at, say, .05 level).
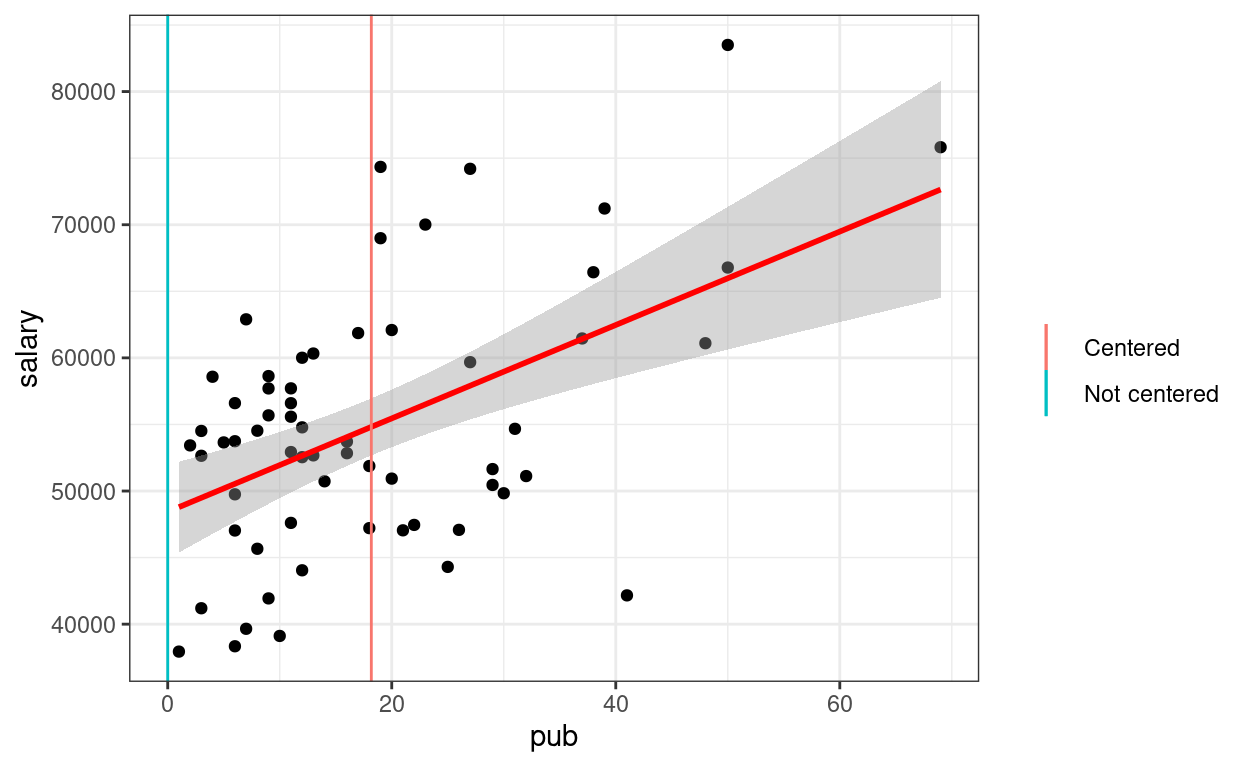
Centering
So that the intercept refers to a more meaningful value. It’s a major issue in multilevel modeling.
\[\text{salary}_i = \beta_0 + \beta_1 \text{pub}^c_i + e_i\]
# Using pipe operator
salary_dat <- salary_dat %>%
mutate(pub_c = pub - mean(pub))
# Equivalent to:
# salary_dat <- mutate(salary_dat,
# pub_c = pub - mean(pub))
m1c <- lm(salary ~ pub_c, data = salary_dat)
summary(m1c)
>#
># Call:
># lm(formula = salary ~ pub_c, data = salary_dat)
>#
># Residuals:
># Min 1Q Median 3Q Max
># -20660 -7397 334 5314 19239
>#
># Coefficients:
># Estimate Std. Error t value Pr(>|t|)
># (Intercept) 54815.8 1071.9 51.14 < 2e-16 ***
># pub_c 350.8 77.2 4.55 2.7e-05 ***
># ---
># Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
>#
># Residual standard error: 8440 on 60 degrees of freedom
># Multiple R-squared: 0.256, Adjusted R-squared: 0.244
># F-statistic: 20.7 on 1 and 60 DF, p-value: 2.71e-05The only change is the intercept coefficient
p1 +
geom_smooth(method = "lm", col = "red") +
# Intercept without centering
geom_vline(aes(col = "Not centered", xintercept = 0)) +
# Intercept with centering
geom_vline(aes(col = "Centered", xintercept = mean(salary_dat$pub))) +
labs(col = "")
2. Categorical Predictor
Recode sex as factor variable in R (which
allows R to automatically do dummy coding). This should be done in
general for categorical predictors.
\[\text{salary}_i = \beta_0 + \beta_1 \text{sex}_i + e_i\]
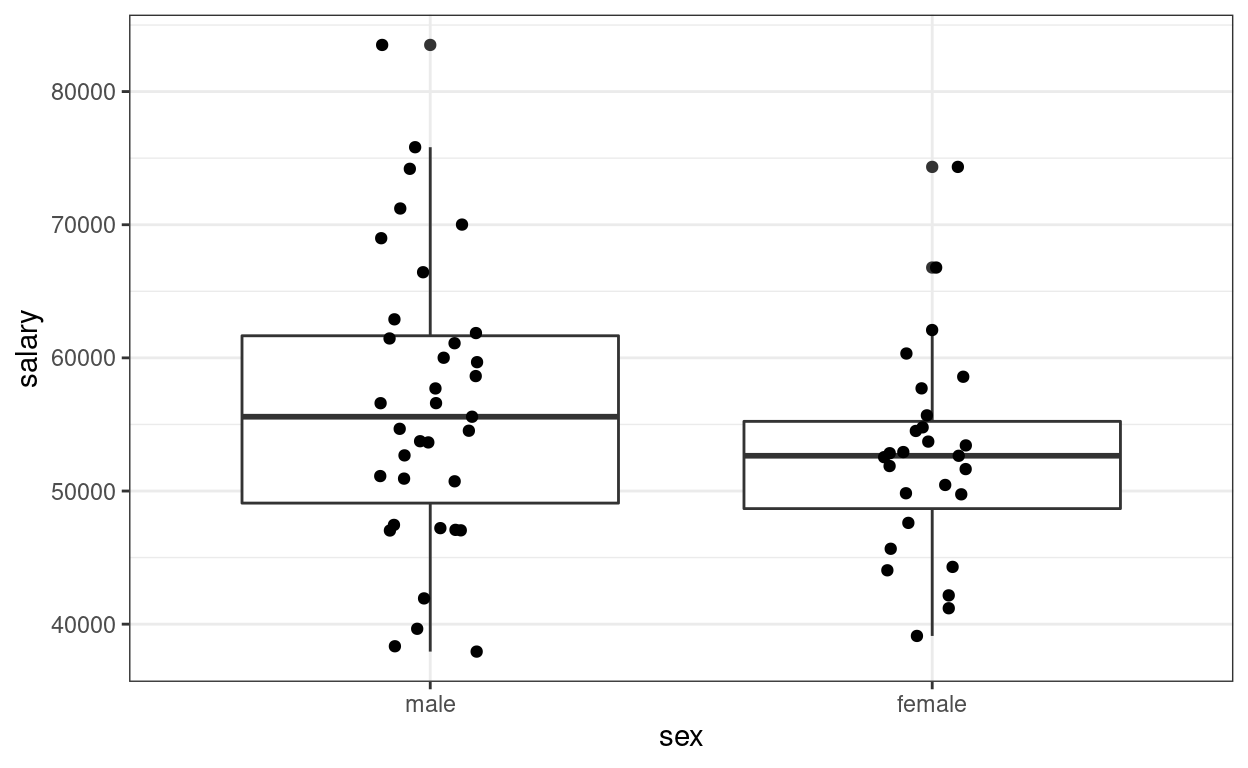
(p2 <- ggplot(salary_dat, aes(x = sex, y = salary)) +
geom_boxplot() +
geom_jitter(height = 0, width = 0.1)) # move the points to left/right a bit
>#
># Call:
># lm(formula = salary ~ sex, data = salary_dat)
>#
># Residuals:
># Min 1Q Median 3Q Max
># -18576 -5736 -19 4853 26988
>#
># Coefficients:
># Estimate Std. Error t value Pr(>|t|)
># (Intercept) 56515 1620 34.88 <2e-16 ***
># sexfemale -3902 2456 -1.59 0.12
># ---
># Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
>#
># Residual standard error: 9590 on 60 degrees of freedom
># Multiple R-squared: 0.0404, Adjusted R-squared: 0.0244
># F-statistic: 2.53 on 1 and 60 DF, p-value: 0.117The (Intercept) coefficient is for the ‘0’ category,
i.e., predicted salary for males; the female coefficient is
the difference between males and females.
Predicted female salary = 56515 + (-3902) = 52613.
Equivalence to the \(t\)-test
When assuming homogeneity of variance
t.test(salary ~ sex, data = salary_dat, var.equal = TRUE)
>#
># Two Sample t-test
>#
># data: salary by sex
># t = 1.6, df = 60, p-value = 0.1
># alternative hypothesis: true difference in means between group male and group female is not equal to 0
># 95 percent confidence interval:
># -1010 8814
># sample estimates:
># mean in group male mean in group female
># 56515 526133. Multiple Predictors (Multiple Regression)
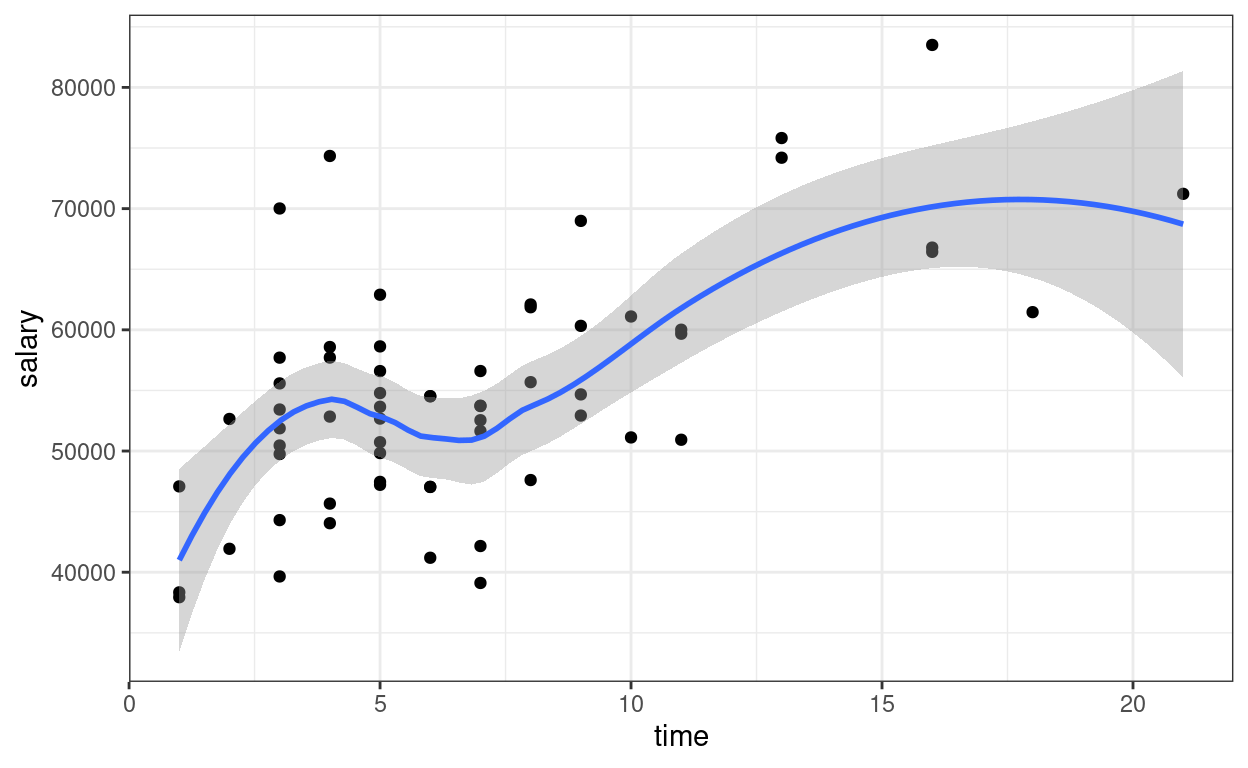
Now add one more predictor, time \[\text{salary}_i = \beta_0 + \beta_1
\text{pub}^c_i + \beta_2 \text{time}_i + e_i\]
ggplot(salary_dat, aes(x = time, y = salary)) +
geom_point() +
geom_smooth()
>#
># Call:
># lm(formula = salary ~ pub_c + time, data = salary_dat)
>#
># Residuals:
># Min 1Q Median 3Q Max
># -15919 -5537 -985 4861 22476
>#
># Coefficients:
># Estimate Std. Error t value Pr(>|t|)
># (Intercept) 47373.4 2281.8 20.76 < 2e-16 ***
># pub_c 133.0 92.7 1.43 0.15680
># time 1096.0 303.6 3.61 0.00063 ***
># ---
># Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
>#
># Residual standard error: 7700 on 59 degrees of freedom
># Multiple R-squared: 0.391, Adjusted R-squared: 0.37
># F-statistic: 18.9 on 2 and 59 DF, p-value: 4.48e-07confint(m3) # confidence interval
># 2.5 % 97.5 %
># (Intercept) 42807.55 51939.2
># pub_c -52.56 318.6
># time 488.56 1703.5The regression coefficients are the partial effects.

Plotting
The sjPlot::plot_model() function is handy
sjPlot::plot_model(m3, type = "pred", show.data = TRUE,
title = "") # remove title
># $pub_c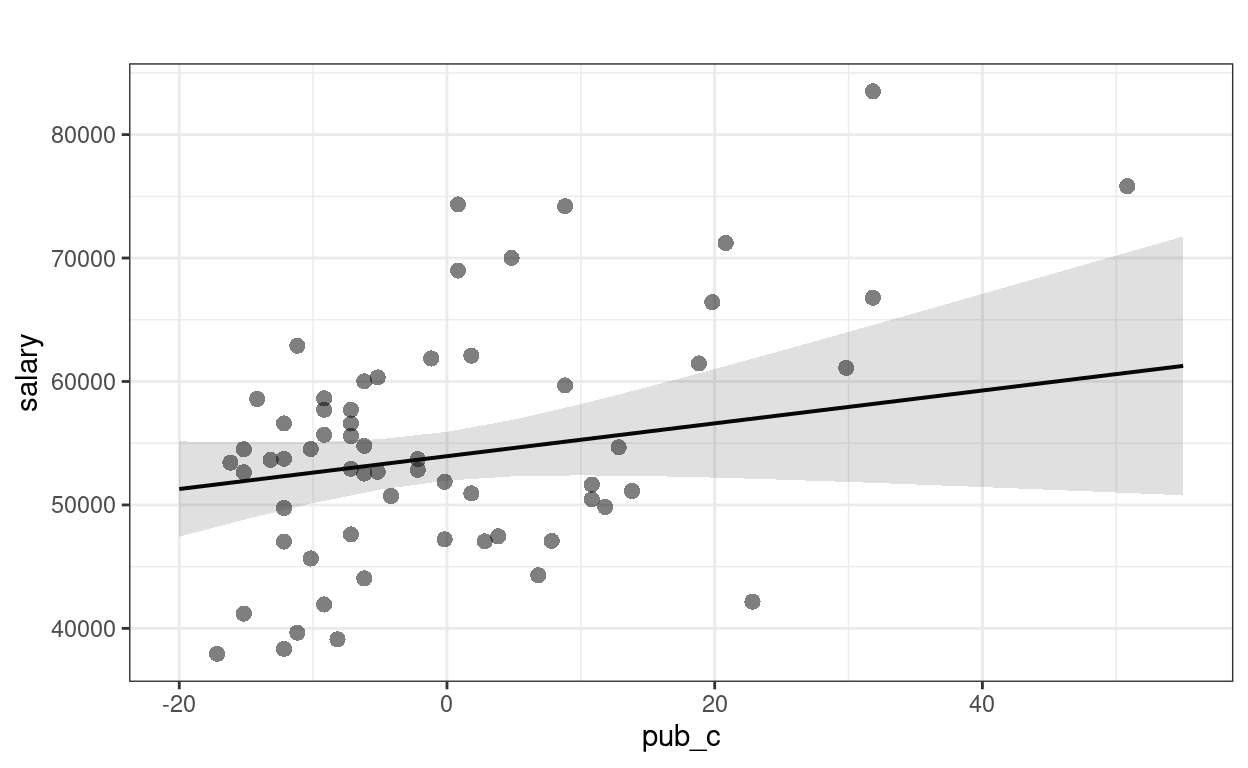
>#
># $time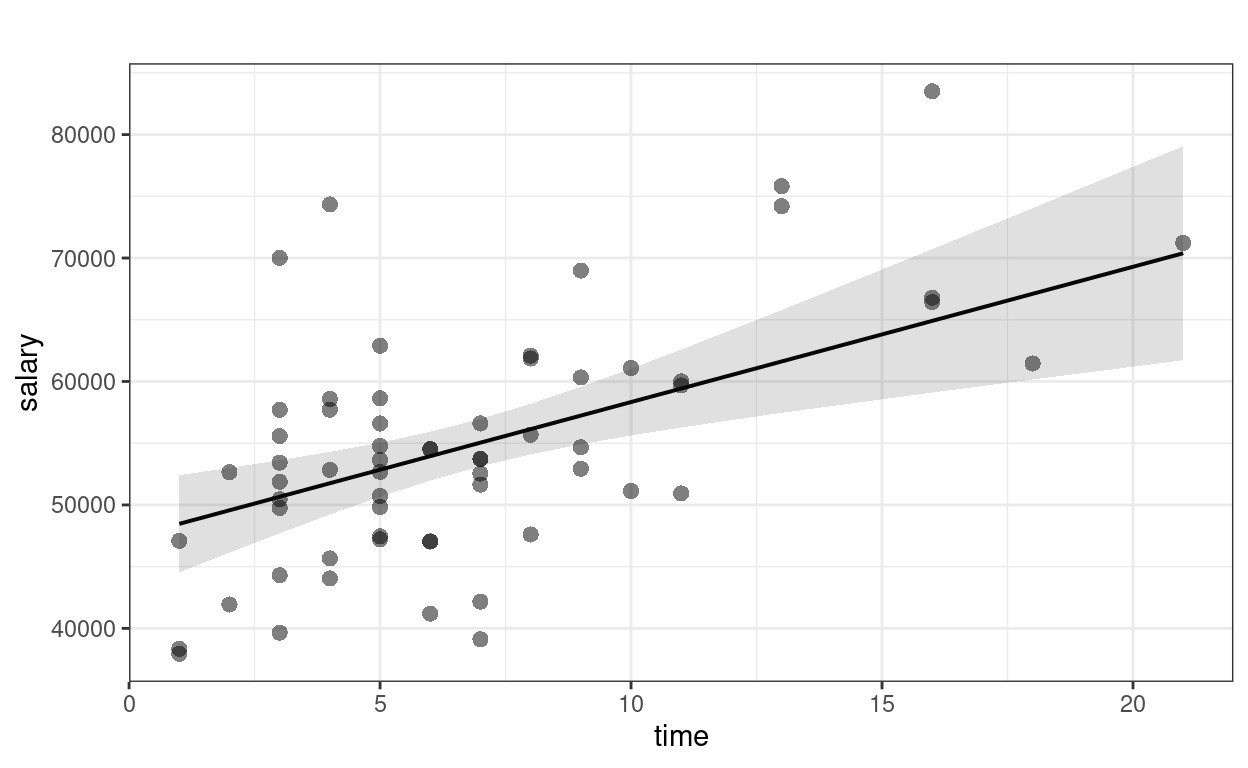
Interpretations
Faculty who have worked longer tended to have more publications For faculty who graduate around the same time, a difference of 1 publication is associated with an estimated difference in salary of $133.0, 95% CI [$-52.6, $318.6], which was not significant.
Diagnostics
car::mmps(m3) # marginal model plots for linearity assumptions
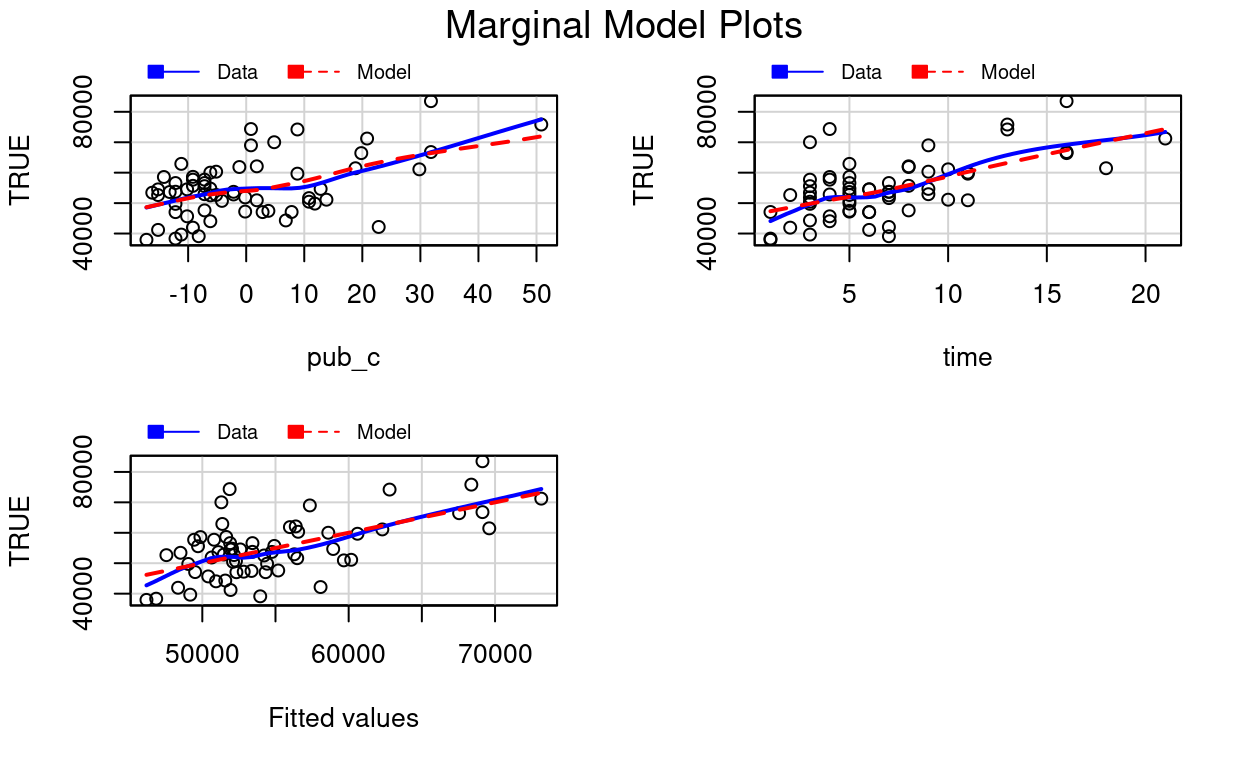
The red line is the implied association based on the model, whereas the blue line is a non-parametric smoother not based on the model. If the two lines show big discrepancies (especially if in the middle), it may suggest the linearity assumptions in the model does not hold.
Effect size
# Extract the R^2 number (it's sometimes tricky to
# figure out whether R stores the numbers you need)
summary(m3)$r.squared
># [1] 0.3908# Adjusted R^2
summary(m3)$adj.r.squared
># [1] 0.3701Proportion of predicted variance: \(R^2\) = 39%, adj. \(R^2\) = 37%.
4. Interaction
For interpretation purposes, it’s recommended to center the predictors (at least the continuous ones)
\[\text{salary}_i = \beta_0 + \beta_1 \text{pub}^c_i + \beta_2 \text{time}^c_i + \beta_3 (\text{pub}^c_i)(\text{time}^c_i) + e_i\]
salary_dat <- salary_dat %>%
mutate(time_c = time - mean(time))
# Fit the model with interactions:
m4 <- lm(salary ~ pub_c * time_c, data = salary_dat)
summary(m4) # summary
>#
># Call:
># lm(formula = salary ~ pub_c * time_c, data = salary_dat)
>#
># Residuals:
># Min 1Q Median 3Q Max
># -14740 -5305 -373 4385 22744
>#
># Coefficients:
># Estimate Std. Error t value Pr(>|t|)
># (Intercept) 54238.1 1183.0 45.85 <2e-16 ***
># pub_c 104.7 98.4 1.06 0.2917
># time_c 964.2 339.7 2.84 0.0062 **
># pub_c:time_c 15.1 17.3 0.87 0.3866
># ---
># Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
>#
># Residual standard error: 7720 on 58 degrees of freedom
># Multiple R-squared: 0.399, Adjusted R-squared: 0.368
># F-statistic: 12.8 on 3 and 58 DF, p-value: 1.56e-06Interaction Plots
Interpreting interaction effects is hard. Therefore,
Always plot the interaction to understand the dynamics
interactions::interact_plot(m4,
pred = "pub_c",
modx = "time_c",
# Insert specific values to plot the slopes.
# Pay attention that `time_c` has been centered
modx.values = c(1, 7, 15) - 6.79,
modx.labels = c(1, 7, 15),
plot.points = TRUE,
x.label = "Number of publications (mean-centered)",
y.label = "Salary",
legend.main = "Time since Ph.D."
)
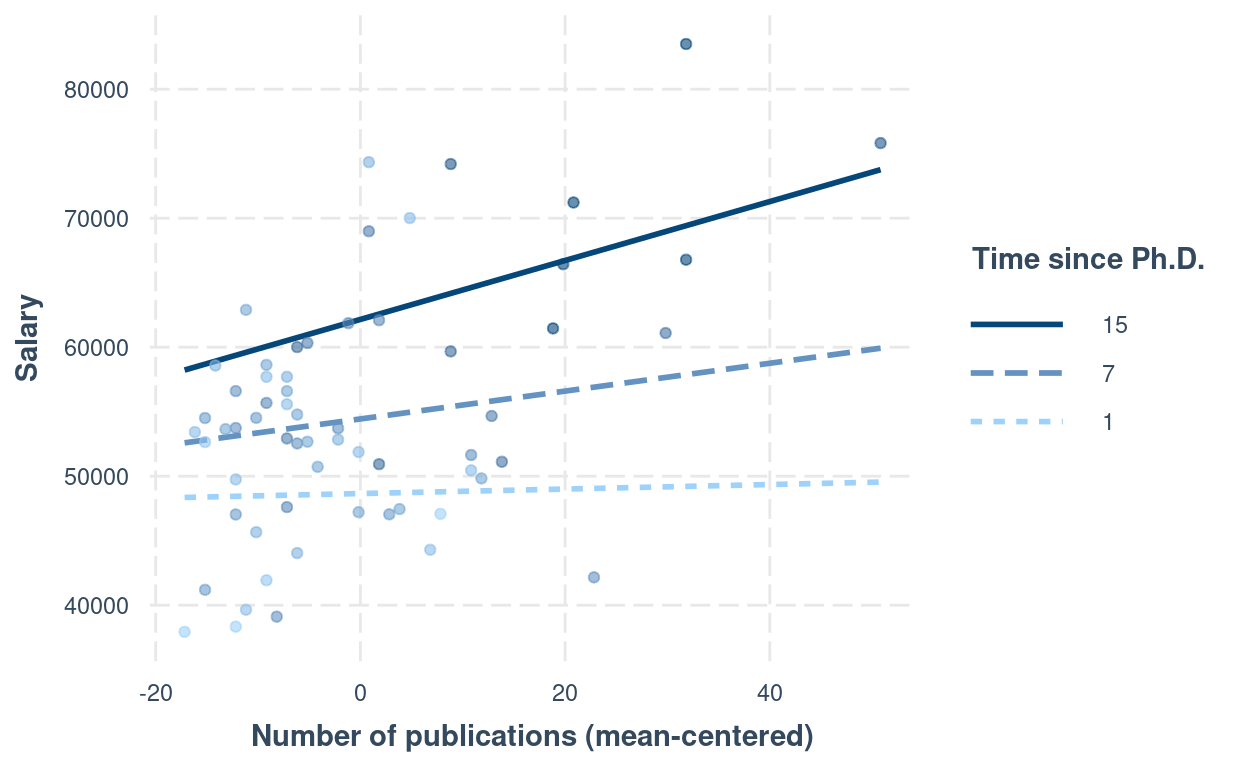
Another approach is to plug in numbers to the equation: \[\widehat{\text{salary}} = \hat \beta_0 + \hat
\beta_1 \text{pub}^c + \hat \beta_2 \text{time}^c + \hat \beta_3
(\text{pub}^c)(\text{time}^c)\] For example, consider people
who’ve graduated for seven years, i.e., time = 7. First, be
careful that in the model we have time_c, and
time = 7 corresponds to time_c = 0.2097 years.
So if we plug that into the equation, \[\widehat{\text{salary}} |_{\text{time} = 7} =
\hat \beta_0 + \hat \beta_1 \text{pub}^c + \hat \beta_2 (0.21) + \hat
\beta_3 (\text{pub}^c)(0.21)\] Combining terms with
pubc, \[\widehat{\text{salary}}
|_{\text{time} = 7} = [\hat \beta_0 + \hat \beta_2 (0.21)] + [\hat
\beta_1 + \hat \beta_3 (0.21)] (\text{pub}^c)\] Now plug in the
numbers for \(\hat \beta_0\), \(\hat \beta_1\), \(\hat \beta_2\), \(\hat \beta_3\),
# beta0 + beta2 * 0.21
54238.08 + 964.17 * 0.21
># [1] 54441# beta1 + beta3 * 0.21
104.72 + 15.07 * 0.21
># [1] 107.9resulting in \[\widehat{\text{salary}}
|_{\text{time} = 7} = 54440.6 + 107.9 (\text{pub}^c), \] which is
the regression line for time = 7. Note, however, when an
interaction is present, the regression slope will be different with a
different value of time. So remember that
An interaction means that the regression slope of a predictor depends on another predictor.
We will further explore this in the class exercise this week.
5. Tabulate the Regression Results
msummary(list(
"M1" = m1,
"M2" = m2,
"M3" = m3,
"M3 + Interaction" = m4
),
fmt = "%.1f"
) # keep one digit
| M1 | M2 | M3 | M3 + Interaction | |
|---|---|---|---|---|
| (Intercept) | 48439.1 | 56515.1 | 47373.4 | 54238.1 |
| (1765.4) | (1620.5) | (2281.8) | (1183.0) | |
| pub | 350.8 | |||
| (77.2) | ||||
| sexfemale | −3902.1 | |||
| (2455.6) | ||||
| pub_c | 133.0 | 104.7 | ||
| (92.7) | (98.4) | |||
| time | 1096.0 | |||
| (303.6) | ||||
| time_c | 964.2 | |||
| (339.7) | ||||
| pub_c × time_c | 15.1 | |||
| (17.3) | ||||
| Num.Obs. | 62 | 62 | 62 | 62 |
| R2 | 0.256 | 0.040 | 0.391 | 0.399 |
| R2 Adj. | 0.244 | 0.024 | 0.370 | 0.368 |
| AIC | 1301.0 | 1316.8 | 1290.6 | 1291.8 |
| BIC | 1307.4 | 1323.1 | 1299.1 | 1302.4 |
| Log.Lik. | −647.486 | −655.383 | −641.299 | −640.895 |
| F | 20.665 | 2.525 | 18.922 | 12.817 |
| RMSE | 8440.40 | 9586.92 | 7703.16 | 7718.81 |
Bonus: Matrix Form of Regression
The regression model can be represented more succintly in matrix form: \[\bv y = \bv X \bv \beta + \bv e,\] where \(\bv y\) is a column vector (which can be considered a \(N \times 1\) matrix). For example, for our data
head(salary_dat)
># id time pub sex citation salary pub_c time_c
># 1 1 3 18 female 50 51876 -0.1774 -3.7903
># 2 2 6 3 female 26 54511 -15.1774 -0.7903
># 3 3 3 2 female 50 53425 -16.1774 -3.7903
># 4 4 8 17 male 34 61863 -1.1774 1.2097
># 5 5 9 11 female 41 52926 -7.1774 2.2097
># 6 6 6 6 male 37 47034 -12.1774 -0.7903So \[\bv y = \begin{bmatrix} 51,876 \\ 54,511 \\ 53,425 \\ \vdots \end{bmatrix}\] \(\bv X\) is the predictor matrix (sometimes also called the design matrix), where the first column is the constant 1, and each subsequent column represent a predictor. You can see this in R
head(
model.matrix(m3)
)
># (Intercept) pub_c time
># 1 1 -0.1774 3
># 2 1 -15.1774 6
># 3 1 -16.1774 3
># 4 1 -1.1774 8
># 5 1 -7.1774 9
># 6 1 -12.1774 6The coefficient \(\bv \beta\) is a vector, with elements \(\beta_0, \beta_1, \ldots\). The least square estimation method is used to find estimates of \(\beta\) that minimizes the sum of squared differences between \(\bv y\) and \(\bv X \hat{\bv \beta}\), which can be written as \[(\bv y - \bv X \bv \beta)^\top(\bv y - \bv X \bv \beta).\] The above means that: for each value observation, subtract the predicted value of \(y\) from the observed \(y\) (i.e., \(y_i - \beta_0 + \beta_1 x_{1i} + \ldots\)), then squared the value (\([y_i - \beta_0 + \beta_1 x_{1i} + \ldots]^2\)), then sum these squared values across observations. Or sometimes you’ll see it written as \[\lVert\bv y - \bv X \bv \beta)\rVert^2\] It can be shown that the least square estimates can be obtained as \[(\bv X^\top \bv X)^{-1} \bv X^\top \bv y\] You can do the matrix form in R:
y <- salary_dat$salary
X <- model.matrix(m3)
# beta = (X'X)^{-1} X'y
# solve() is matrix inverse; t(X) is the transpose of X; use `%*%` for matrix multiplication
(betahat <- solve(t(X) %*% X, t(X) %*% y)) # same as the coefficients in m3
># [,1]
># (Intercept) 47373
># pub_c 133
># time 1096># [1] 3.501e+09# Root mean squared residual (Residual standard error)
sqrt(sum((y - X %*% betahat)^2) / 59) # same as in R
># [1] 7703Bonus: More Options in Formatting Tables
Here’s some code you can explore to make the table output from
msummary() to look more lik APA style (with an example
here: https://apastyle.apa.org/style-grammar-guidelines/tables-figures/sample-tables#regression).
However, for this course I don’t recommend spending too much time on
tailoring the tables; something clear and readable will be good
enough.
# Show confidence intervals and p values
msummary(
list(
"Estimate" = m4,
"95% CI" = m4,
"p" = m4
),
estimate = c("estimate", "[{conf.low}, {conf.high}]", "p.value"),
statistic = NULL,
# suppress gof indices (e.g., R^2)
gof_omit = ".*",
# Rename the model terms ("current name" = "new name")
coef_rename = c(
"(Intercept)" = "Intercept",
"pub_c" = "Number of publications",
"time_c" = "Time since PhD",
"pub_c:time_c" = "Publications x Time"
)
)
| Estimate | 95% CI | p | |
|---|---|---|---|
| Intercept | 54238.084 | [51870.023, 56606.145] | 0.000 |
| Number of publications | 104.724 | [−92.273, 301.720] | 0.292 |
| Time since PhD | 964.170 | [284.218, 1644.122] | 0.006 |
| Publications x Time | 15.066 | [−19.506, 49.637] | 0.387 |